Self-Supervised Learning Methods
An exploration of modern self-supervised learning methods including SimCLR, BYOL, SimSiam, Barlow Twins, DINO, etc, with mathematical foundations and mutual information theory
Tech Stack
Tags
Self-Supervised Learning Methods: A Comprehensive Introduction
Self-supervised learning (SSL) has revolutionized deep learning by enabling models to learn powerful representations without labeled data. This note provides a deep dive into five major SSL paradigms and their representative methods.
Table of Contents
- Introduction
- Core Concepts
- Contrastive Learning
- Predictive/Bootstrap Learning
- Redundancy Reduction
- Clustering-based SSL
- Generative SSL
- Mathematical Foundations
- Summary
Introduction
Self-supervised learning addresses a fundamental question: Can we learn good representations without labels?
My first impression of SSL came from Dr. Yann LeCun's lecture, where I first heard about the fascinating idea of joint embedding (highly recommend Alfredo Canziani's notes).
What "Joint Embedding" Means
Embedding = mapping an input (image, sentence, etc.) into a vector representation .
Joint = you learn two (or more) embeddings of the same underlying object — usually two augmented views — and train the system so that these embeddings are related in a desired way.
So a joint embedding method learns a function such that for two correlated inputs :
and the training objective makes and similar (while keeping them informative).
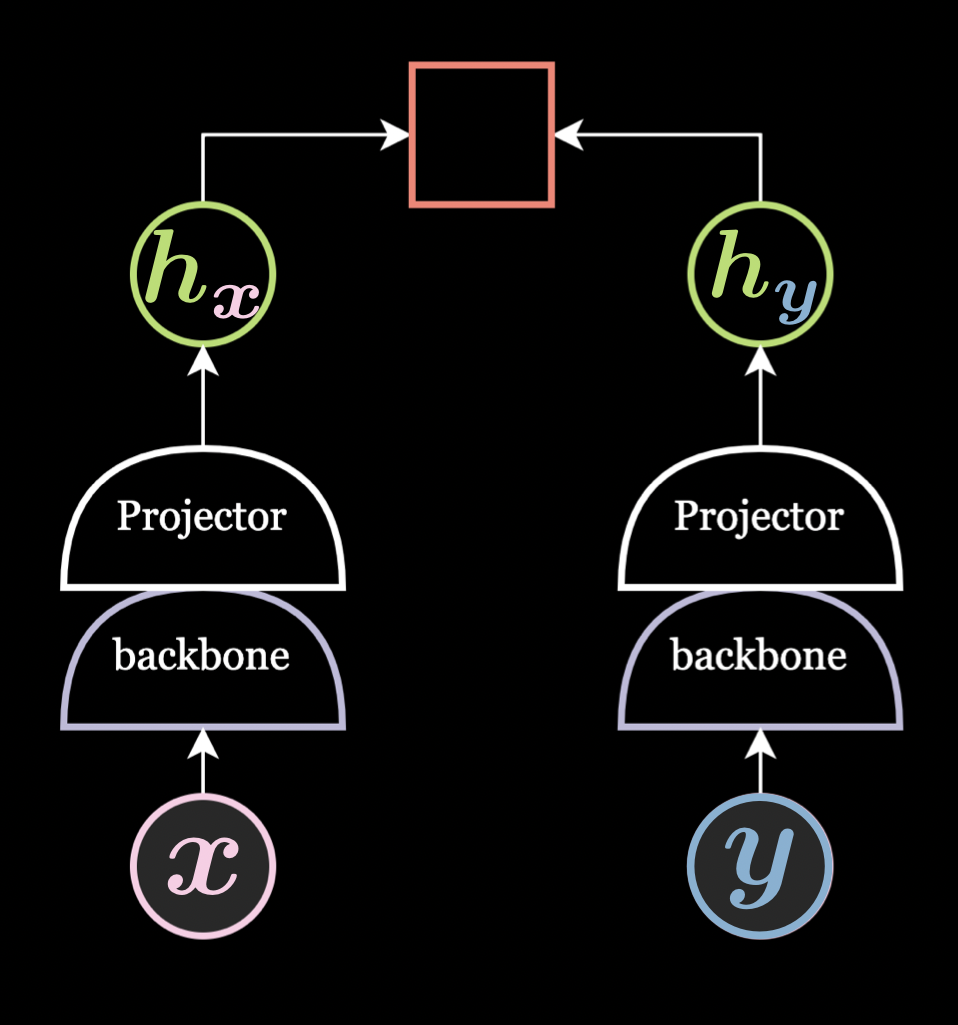 Joint Embedding Method, by Alfredo Canziani and Jiachen Zhu
Joint Embedding Method, by Alfredo Canziani and Jiachen Zhu
All SSL methods balance two competing forces:
- Invariance: Make representations stable under data augmentations
- Information preservation: Avoid trivial constant outputs (collapse)
Different SSL families handle this trade-off in unique ways.
Core Concepts
Mutual Information (MI)
For two random variables and :
In SSL, we want embeddings , (from two augmented views) that share semantic information (high MI).
The Collapse Problem
If we only minimize without constraints, the network collapses to outputting constants, resulting in .
SSL Family Comparison
Different SSL families use different mechanisms to prevent collapse and estimate mutual information:
All modern SSL objectives can be written conceptually as:
where regularizes representations (avoid trivial solutions).
| Family | Representative Models | Core Objective | Regularizer | MI Estimation Mechanism |
|---|---|---|---|---|
| Contrastive | SimCLR, MoCo, SwAV | Discriminate positives vs negatives | implicit via negatives | InfoNCE lower bound |
| Predictive / Bootstrap | BYOL, SimSiam, DINO, iBOT | Predict target view (teacher/student) | asymmetry (EMA / stop-grad) | alignment loss |
| Redundancy Reduction | Barlow Twins, VICReg | Decorrelate and keep variance | variance & covariance penalties | decorrelation |
| Clustering | SwAV, SeLa | Maintain consistent cluster assignment | entropy balancing of prototypes | categorical MI |
| Generative | MAE, BEiT, SimMIM | Reconstruct masked input | reconstruction constraint |
Contrastive Learning
Core Idea: Learn by discriminating positive (same instance) vs. negative (different instance) pairs.
SimCLR (2020)
 SimCLR Illustration, by https://research.google/blog/advancing-self-supervised-and-semi-supervised-learning-with-simclr/
SimCLR Illustration, by https://research.google/blog/advancing-self-supervised-and-semi-supervised-learning-with-simclr/
Pipeline:
- Generate two augmentations of the same image
- Pass through encoder → embeddings
- Add projection MLP : ,
- Apply InfoNCE loss:
Key Insight: Needs large batches or memory banks for good negatives.
Connection to MI: Oord et al. (2018) proved:
So minimizing InfoNCE maximizes a lower bound on MI.
MoCo (Momentum Contrast)
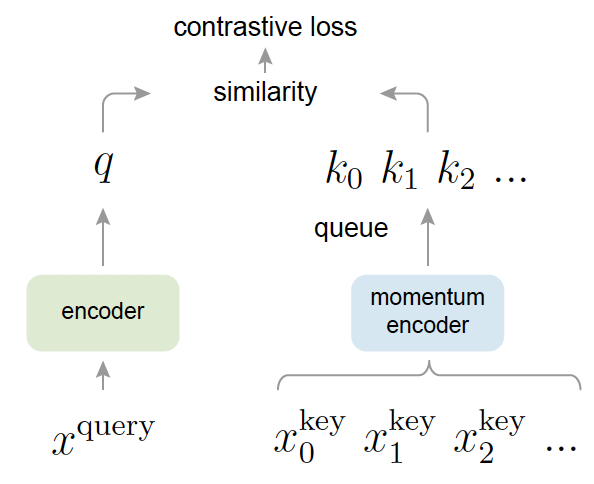 MoCo Illustration, by https://doi.org/10.48550/arXiv.1911.05722
MoCo Illustration, by https://doi.org/10.48550/arXiv.1911.05722
Innovation:
- Maintains a momentum encoder and queue of old embeddings as negatives
- Online encoder updates quickly; momentum encoder updates slowly through Exponential Moving Average (EMA)
- Works with smaller batches
Effect: Stabilizes contrastive training without requiring large batches.
Predictive Bootstrap Learning
Core Idea: Predict one view from another without negatives using asymmetry.
BYOL (Bootstrap Your Own Latent, 2020)
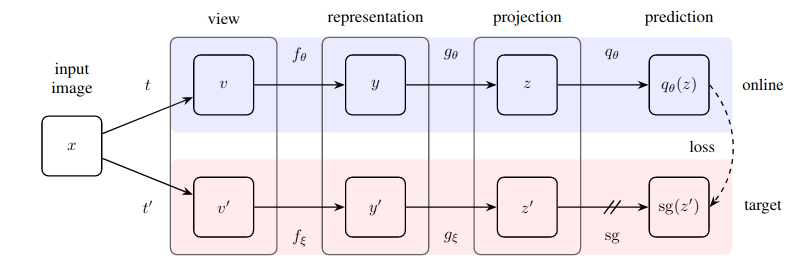 BYOL Illustration, by https://doi.org/10.48550/arXiv.2006.07733
BYOL Illustration, by https://doi.org/10.48550/arXiv.2006.07733
Architecture:
- Online network: encoder , projector , predictor
- Target network: encoder , projector
- Parameters update via EMA:
Loss:
Why It Works: The slow-moving target stabilizes learning and preserves variance.
SimSiam (2021)
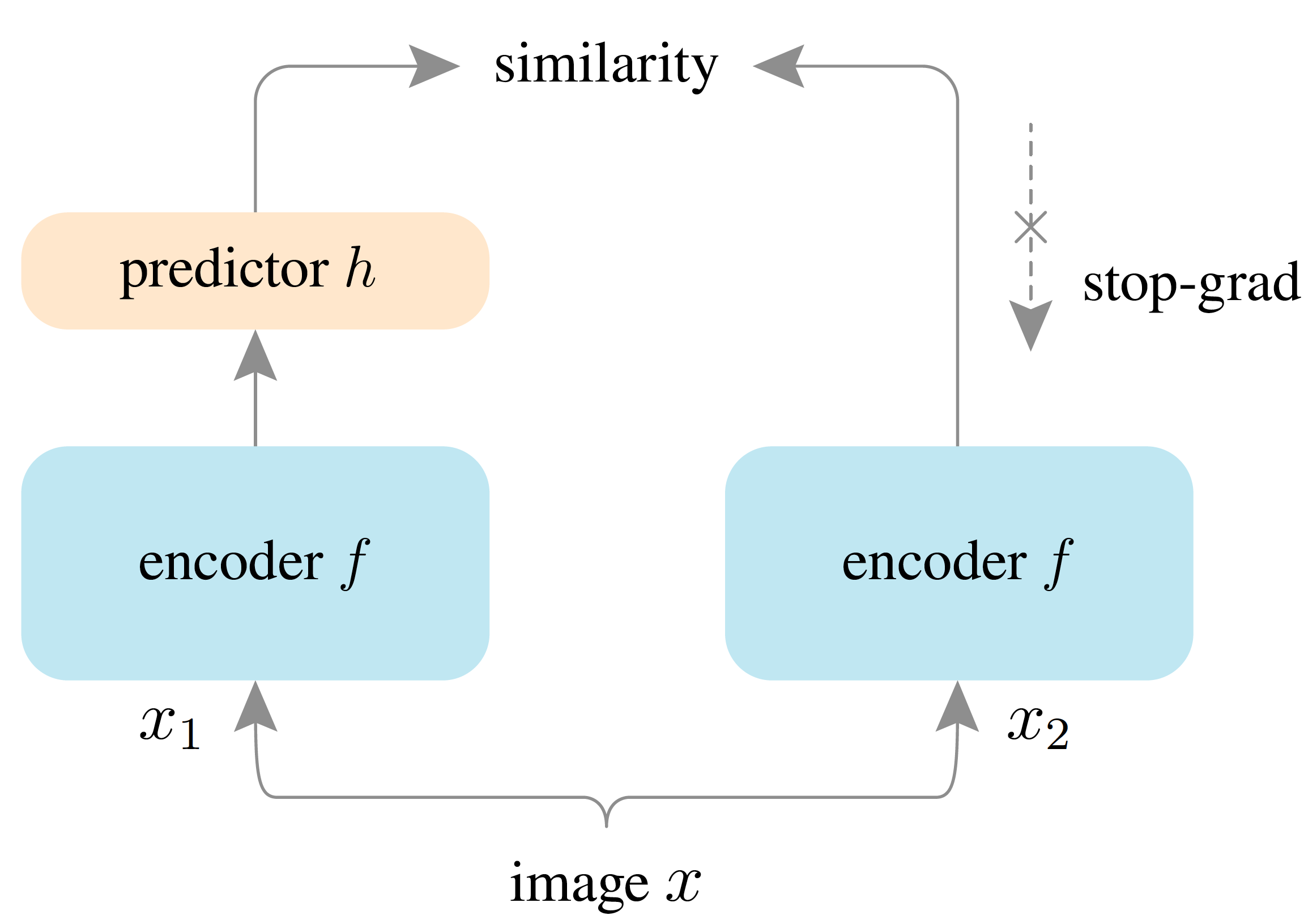 SimSiam Illustration, by https://doi.org/10.48550/arXiv.2011.10566
SimSiam Illustration, by https://doi.org/10.48550/arXiv.2011.10566
Simplification: No momentum encoder!
Mechanism:
- Two identical branches (same encoder + projector)
- One has a predictor on top
- Crucially: stop-gradient on one branch
Loss:
Key Insight: Stop-gradient breaks symmetry and prevents collapse by creating asymmetric gradient flow.
DINO (2021)
 DINO Illustration, by https://doi.org/10.48550/arXiv.2104.14294
DINO Illustration, by https://doi.org/10.48550/arXiv.2104.14294
Extension: Scales BYOL-style training to Vision Transformers.
Mechanism:
- Teacher-student setup with EMA teacher
- Both output soft probability distributions (after softmax)
- Loss: cross-entropy between student and teacher outputs
- Uses centering and sharpening on teacher outputs
Emergence: DINO's embeddings show emergent segmentation—ViTs attend to semantic regions without labels!
iBOT (2022)
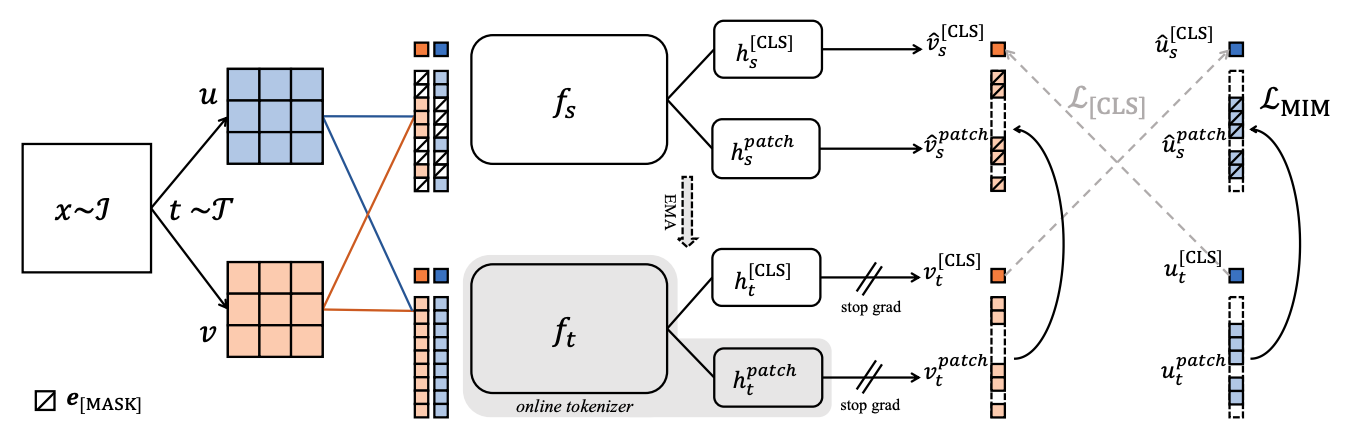 iBOT Illustration, by https://doi.org/10.48550/arXiv.2111.07832
iBOT Illustration, by https://doi.org/10.48550/arXiv.2111.07832
Hybrid: Combines DINO + masked prediction.
Innovation:
- Mask random patches of ViT input
- Predict their teacher-assigned tokens
- Unifies predictive and generative principles
Redundancy Reduction
Core Idea: Encourage invariant, diverse, and decorrelated representations.
Barlow Twins (2021)
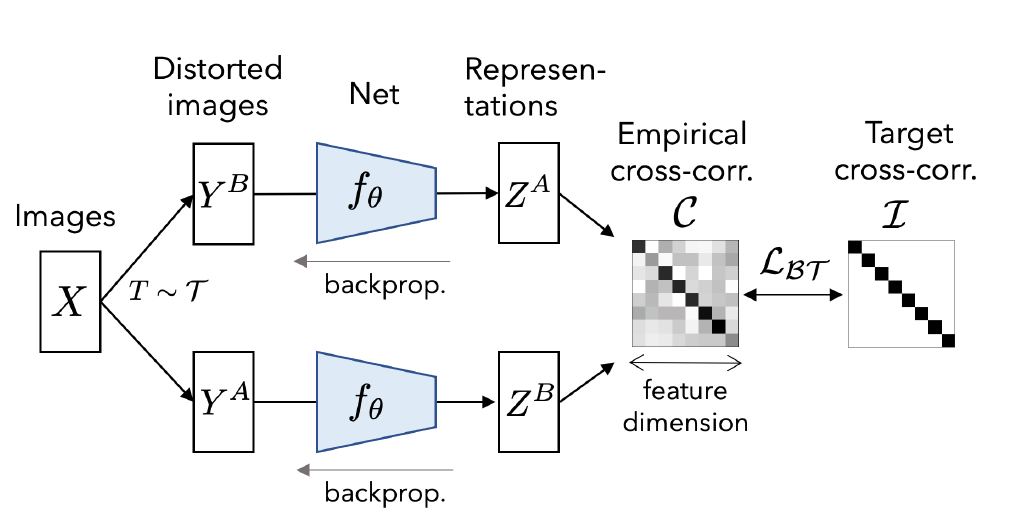 Barlow Twins Illustration, by https://doi.org/10.48550/arXiv.2103.03230
Barlow Twins Illustration, by https://doi.org/10.48550/arXiv.2103.03230
Mechanism:
Compute cross-correlation matrix
Loss:
- Diagonal terms → 1: High per-dimension agreement (↑ MI)
- Off-diagonal → 0: Decorrelate features (prevent collapse)
Interpretation: Under Gaussianity, this approximates maximizing per-dimension MI while preventing "all-info-in-one-dim" collapse.
VICReg (2022)
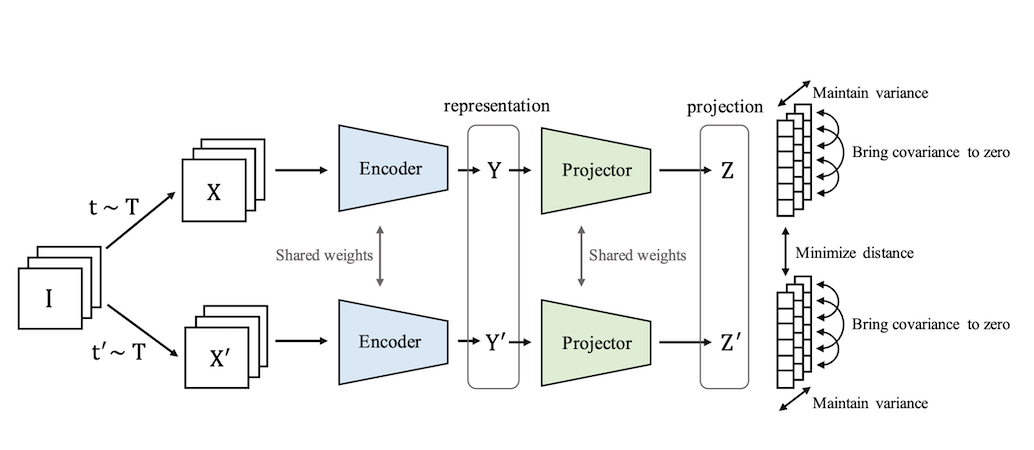 VICReg Twins Illustration, by https://doi.org/10.48550/arXiv.2105.04906
VICReg Twins Illustration, by https://doi.org/10.48550/arXiv.2105.04906
Explicit Decomposition:
Three Terms:
- Invariance: (alignment)
- Variance: (keeps high)
- Covariance: (redundancy reduction)
Advantage: Easier to reason about mathematically; no momentum, stop-grad, or large batches needed.
Clustering-based SSL
Core Idea: Group similar embeddings into prototypes and enforce consistent cluster assignments.
SwAV (2020)
 SwAV Illustration, by https://doi.org/10.48550/arXiv.2006.09882
SwAV Illustration, by https://doi.org/10.48550/arXiv.2006.09882
Hybrid Approach: Merges contrastive and clustering learning.
Mechanism:
- Maintain learnable prototype vectors
- For each augmented view , encode to feature using shared encoder
- Compute soft assignments of features to prototypes using Sinkhorn-Knopp algorithm (enforces balanced cluster usage across batch)
- Predict one view's prototype assignments from another—swap assignments between augmentations
Loss: Cross-entropy between predicted prototype distribution of one view and balanced assignment of the other:
Benefits:
- No explicit negative pairs needed
- Encourages semantic grouping through prototype consistency
- Balanced clustering stabilizes training and accelerates convergence
- Works well even with small batch sizes
Generative SSL
Core Idea: Learn by reconstructing input (or missing parts).
Masked Autoencoder (MAE, 2021)
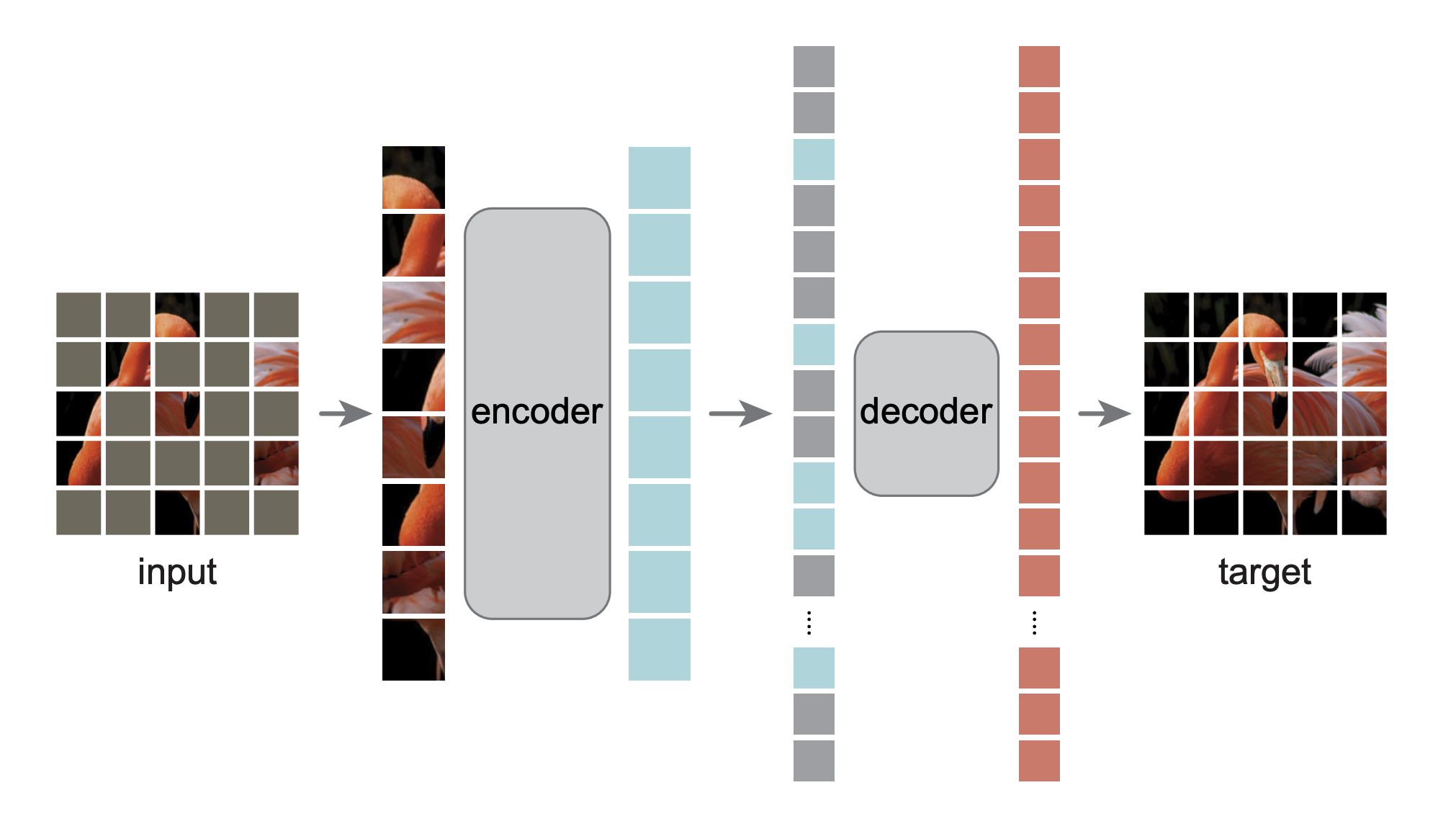 MAE Twins Illustration, by https://doi.org/10.48550/arXiv.2111.06377
MAE Twins Illustration, by https://doi.org/10.48550/arXiv.2111.06377
Mechanism:
- Mask 75% of ViT patches
- Encoder sees only unmasked patches
- Lightweight decoder reconstructs masked pixels
- Loss: MSE on masked patches
Why Effective: Forces encoder to learn global structure without contrastive signals.
Connection to MI: If the decoder models ,
Minimizing reconstruction ≈ minimizing , thus maximizing .
Mathematical Foundations
Unified Framework
All SSL methods can be viewed as:
Loss-to-MI Connections
InfoNCE → MI Lower Bound
With similarity score :
The numerator estimates joint ; negatives approximate marginals .
Cosine/MSE → MI (Gaussian Assumption)
For whitened, approximately Gaussian representations:
If are jointly Gaussian with correlation :
Increasing correlation (reducing ) monotonically increases MI.
Reconstruction → Conditional Entropy
Since , reconstruction maximizes MI.
Barlow Twins → Decorrelated MI
Pushing (high per-dimension MI) and (decorrelation) prevents redundancy while maximizing information.
VICReg → Explicit Regularization
- Invariance raises
- Variance prevents degenerate low-entropy
- Covariance spreads information across dimensions
Under Gaussianity, these terms are direct surrogates for "maximize MI while preventing collapse and redundancy."
Collapse Prevention Mechanisms
| Method | Mechanism |
|---|---|
| SimCLR | Negatives estimate marginal |
| BYOL | EMA teacher provides stable target |
| SimSiam | Stop-gradient creates asymmetry |
| DINO | Temperature sharpening + centering |
| Barlow Twins | Off-diagonal penalty → decorrelation |
| VICReg | Explicit variance regularization |
| SwAV | Entropy balancing of prototypes |
| MAE | Reconstruction constraint |
Summary
Key Insights
- All methods maximize MI between augmented views while preventing collapse
- Negatives are not necessary — asymmetry (EMA/stop-grad) or explicit regularization suffices
- Mathematical elegance varies: VICReg is most interpretable, InfoNCE has strongest theoretical foundation
- Emergence in ViTs: DINO/MAE show that SSL enables semantic understanding without labels
- Hybrid approaches (iBOT, MSN) combine strengths of multiple paradigms
References
- Chen et al. (2020). "A Simple Framework for Contrastive Learning of Visual Representations" (SimCLR)
- Grill et al. (2020). "Bootstrap Your Own Latent" (BYOL)
- Chen & He (2021). "Exploring Simple Siamese Representation Learning" (SimSiam)
- Zbontar et al. (2021). "Barlow Twins: Self-Supervised Learning via Redundancy Reduction"
- Bardes et al. (2022). "VICReg: Variance-Invariance-Covariance Regularization"
- Caron et al. (2021). "Emerging Properties in Self-Supervised Vision Transformers" (DINO)
- He et al. (2021). "Masked Autoencoders Are Scalable Vision Learners" (MAE)
- Zhou et al. (2022). "iBOT: Image BERT Pre-Training with Online Tokenizer"
Conclusion
Self-supervised learning has matured from requiring large batches of negatives (SimCLR) to elegant formulations based on redundancy reduction (VICReg) and masked prediction (DINO). The key insight is that meaningful representations emerge when models balance invariance to augmentations with preservation of information diversity.
The field continues to evolve, with recent work focusing on:
- Scaling to billion-image datasets (DINOv2, SEER)
- Multi-modal learning (CLIP, Data2Vec)
- Efficient training (faster convergence, lower compute)
- Theoretical understanding (why does stop-gradient work?)
Understanding these fundamentals provides a strong foundation for both using and extending self-supervised learning methods.