Building a ChatGPT from Scratch: A Dive into LLM Training
A hands-on journey through the complete LLM pipeline—tokenization, pretraining, distributed training, and fine-tuning—inspired by Andrej Karpathy's nanochat. Training a 561M parameter conversational model on 11.2B tokens to understand different aspects of modern language models.
Tech Stack
Tags
Try the model above — it's a 561M parameter model trained from scratch. It makes mistakes, it hallucinates, and it's a bit naive, but it's fun.
Motivation
Large Language Models have transformed AI, but their training pipelines remain opaque to myself. When I encountered Andrej Karpathy's nanochat project, I saw an opportunity to get my hands dirty with every stage of LLM development—not just fine-tuning pre-trained models, but building one from the ground up.
This project wasn't about competing with GPT-4. It was about understanding the fundamentals:
- How does tokenization affect model efficiency?
- What happens during distributed pretraining?
- How do you transition from next-token prediction to conversational AI?
- What trade-offs exist between model size, data, and compute?
As someone aiming to apply deep learning to model biological systems, these foundational skills—handling large-scale data, distributed training, and representation learning—are directly transferable. The techniques that enable LLMs to compress human language into vector spaces can similarly help compress the complexity of cellular processes, gene expression patterns, and protein interactions.
Technical Overview
Architecture: GPT-Style Decoder-Only Transformer
Model Specifications:
- Parameters: 561 million (d20 configuration: 20 layers)
- Context Length: 2048 tokens
- Vocabulary: 65,536 tokens (custom BPE tokenizer)
- Hidden Dimension: 1024
- Attention Heads: 16
- Activation: GELU
Training Infrastructure:
- Hardware: 8× NVIDIA A100-SXM4-80GB GPUs (634GB total VRAM)
- Framework: PyTorch 2.8.0 with Distributed Data Parallel (DDP)
- Platform: Lambda Labs cloud (CUDA 12.8 on Linux)
- Total Cost: ~14.32/hour)
- Model FLOPs Utilization (MFU): 20.82%
The Complete Training Pipeline
Stage 1: Custom Tokenizer Training
Instead of using GPT-2's tokenizer, a custom Byte Pair Encoding (BPE) tokenizer was trained from scratch on 2 billion characters from the FineWeb-Edu dataset.
Performance vs. Baselines:
| Domain | vs GPT-2 | vs GPT-4 |
|---|---|---|
| News | +7.2% | +3.1% |
| Science | +12.3% | +8.4% |
| Code | +14.4% | -59.5% |
| Math | -3.2% | -16.1% |
Key Insight: The tokenizer excels at scientific text and natural language (the training domain) but underperforms on code and multilingual data (expected, since FineWeb-Edu is English-heavy). This demonstrates the importance of domain-matched tokenization, a critical consideration for future applications in computational biology where domain-specific vocabularies (gene names, protein sequences, chemical compounds) require specialized tokenization strategies.
Compression Ratio: 4.91 bytes/token (competitive with GPT-2's 4.67 and GPT-4's 4.81)
Training Time: 1.6 minutes on 8xA100
Stage 2: Base Model Pretraining (21,400 iterations)
This is where the model learns language understanding through next-token prediction on unlabeled text.
Training Details:
- Data: FineWeb-Edu dataset (filtered Wikipedia and educational web content)
- Tokens Processed: 11.2 billion tokens (20:1 token-to-parameter ratio)
- Batch Size: 524,288 tokens (distributed across 8 GPUs)
- Learning Rate Schedule:
- Matrix parameters: 0.02 (cosine decay with 20% warmdown)
- Embedding: 0.2 (10× higher for faster vocabulary learning)
- Unembedding: 0.004 (lower to stabilize output logits)
- Optimizer: AdamW with weight decay 0.0
- Training Time: 6.6 hours
- Final Validation Loss: 0.8156 bits per byte
Why Different Learning Rates? This tiered approach (borrowed from nanochat's modded-nanoGPT optimizations) stabilizes training:
- High embedding LR: Vocabulary embeddings need to move quickly to capture semantic relationships
- Low unembedding LR: Output layer overfitting prevention
- Medium matrix LR: Balances generalization and convergence
Base Model Evaluation (CORE Benchmark):
| Task | Score | Interpretation |
|---|---|---|
| HellaSwag | 0.2559 | Commonsense reasoning |
| Winograd | 0.3040 | Pronoun disambiguation |
| ARC-Easy | 0.5174 | Elementary science questions |
| ARC-Challenge | 0.1251 | Advanced reasoning |
| LAMBADA | 0.3775 | Long-range context |
| SQuAD | 0.2260 | Reading comprehension |
CORE Score: 0.2087 (composite metric showing GPT-1.5 level performance)
Example Completions (before chat tuning):
Prompt: "The capital of France is"
Output: "Paris. It is the largest city in France and the capital of the country."
Prompt: "The chemical symbol of gold is"
Output: "Au. It is a soft, silvery-white metal that is malleable and ductile."
Stage 3: Midtraining (765 iterations)
Purpose: Domain adaptation to chat-style formatting and more diverse text sources.
Data: Transition from pure web text to conversational/instruction-following data
Training Time: 30 minutes
Minimum Validation Loss: 0.3976 bpb (significant drop from base model, indicating successful adaptation)
Stage 4: Supervised Fine-Tuning (SFT) for Chat (651 iterations)
This stage transforms the base model into a conversational assistant by training on 20,843 human-AI conversations.
Training Configuration:
- Data: SmolTalk dataset (HuggingFace)
- Epochs: 1 (to avoid overfitting on small instruction dataset)
- Batch Size: Effective 32 examples per step (4 per GPU × 8 GPUs)
- Loss Masking: Only compute loss on AI responses (not user prompts)
- Training Time: 24 minutes
- Final Validation Loss: 1.0189
Chat Model Benchmarks:
| Benchmark | Score | Task Type |
|---|---|---|
| ARC-Easy | 0.4571 | Science QA |
| ARC-Challenge | 0.3430 | Complex reasoning |
| MMLU | 0.3396 | Multitask knowledge |
| GSM8K | 0.0500 | Math word problems |
| HumanEval | 0.0793 | Code generation |
| ChatCORE | 0.1298 | Composite chat quality |
Observations:
- Strong improvement on conversational tasks (ARC-Easy: 0.5174 → 0.4571 apparent drop is actually redistribution toward better calibration)
- Weak math/code performance (expected without domain-specific data)
- Model is helpful but hallucinatory — perfect for understanding alignment challenges
Key Learnings
1. Distributed Training Complexity
Managing 8 GPUs with PyTorch DDP taught me about:
- Gradient Synchronization: AllReduce operations across devices
- Batch Size Scaling: Total batch = device_batch × num_gpus × gradient_accumulation
- VRAM Management: Peak usage 75.4 GiB per GPU (out of 80 GB)
- Efficient Checkpointing: Saving optimizer states across multiple devices
2. Data Efficiency Matters More Than Raw Compute
The 20:1 token-to-parameter ratio is a critical heuristic:
- Too few tokens → underfitting
- Too many tokens → diminishing returns (Chinchilla scaling laws suggest 20:1 is near-optimal for smaller models)
My Takeaway: For resource-constrained training, carefully curating high-quality data (FineWeb-Edu beats raw Common Crawl) gives better ROI than just adding more compute.
3. The Fine-Tuning Phase Is Delicate
Overfitting Risk: With only 20K chat examples, epoch=1 was crucial. At epoch=2, validation loss increased (could be memorization).
Instruction Format Matters: SmolTalk uses a clean <|user|>...<|assistant|>... format. Inconsistent formatting breaks chat performance.
4. Evaluation Requires Nuance
CORE/ChatCORE Metrics: Composite scores across multiple benchmarks give a holistic view, but:
- GSM8K (math) is sensitive to output format (model needs to generate "\n#### 42" style answers)
- HumanEval (code) requires exact syntax—close doesn't count
- HellaSwag (commonsense) tests world knowledge, not just language
Human Evaluation: Metrics don't capture personality, coherence, or safety. Playing with the live demo reveals quirks no benchmark shows.
Connections to Biological Modeling
This project directly supports my goal of applying AI to computational biology:
1. Representation Learning:
- LLMs learn compressed representations of language → similar approaches for gene expression (genes/cells as "tokens", pathways as "context")
- Tokenization strategies → how to discretize continuous biological signals
2. Self-Supervised Learning:
- Pretraining on unlabeled text → pretraining on unlabeled spatial transcriptomics (see my SSL on MOSTA project)
- Next-token prediction → masking gene expressions and reconstructing
3. Scale and Efficiency:
- Training 561M parameters in 8 hours → how to scale graph neural networks on millions of cells?
- Distributed training patterns → processing large tissue atlases
4. Transfer Learning:
- LLM fine-tuning → adapting pretrained biological models to new tissues/diseases
Live Demo
🎯 Try it yourself: https://huggingface.co/spaces/BrianGuo/nanochat-20b-chat
Suggested Prompts:
- "Explain how photosynthesis works"
- "Write a short poem about the cloud"
- "Tell me a story about a robot learning to paint"
Expected Behavior: The model will provide coherent, often accurate responses but may hallucinate facts (especially for niche topics) or struggle with multi-step reasoning. But it's good at story telling and teaching with the examples I tried.
Model Files & Reproducibility
All model checkpoints and training reports are available:
Repository: github.com/Thewhey-Brian/nanochat (forked from Karpathy's original)
HuggingFace Model: BrianGuo/nanochat-20b-chat
Local Training Artifacts:
- Custom tokenizer:
tokenizer.pkl,token_bytes.pt - Base model checkpoint:
base_checkpoints/d20/model_021400.pt - Chat SFT checkpoint:
chatsft_checkpoints/d20/model_000650.pt
Future Directions
1. Reinforcement Learning (GRPO):
- Current model is SFT-only → adding PPO for alignment
- Reward model training on preference data
2. Efficient Fine-Tuning:
- LoRA/QLoRA for domain adaptation without full retraining
- Exploring how biological foundation models could use similar techniques
3. Multilingual Extension:
- Current tokenizer is English-biased → train on multilingual corpus (maybe in biological language)
- Study how polyglot tokenization affects model capacity
4. Scaling Laws Exploration:
- Train d26 (1.9B params) and d32 models to verify Chinchilla scaling predictions
- Quantify compute vs. performance trade-offs
Acknowledgments
Inspiration: This work stands on the shoulders of Andrej Karpathy, whose nanochat project makes LLM training accessible to individuals. His educational philosophy—making complex systems hackable—is something I deeply admire.
Compute: Lambda Labs GPU Cloud for reliable 8xA100 access
Data: HuggingFace for FineWeb-Edu and SmolTalk datasets
Community: The open-source ML community for PyTorch, Transformers, and countless tutorials
Sample Model Outputs
Thanks for reading! Here are some little treats - fun outputs from the trained model that showcase its personality and capabilities:
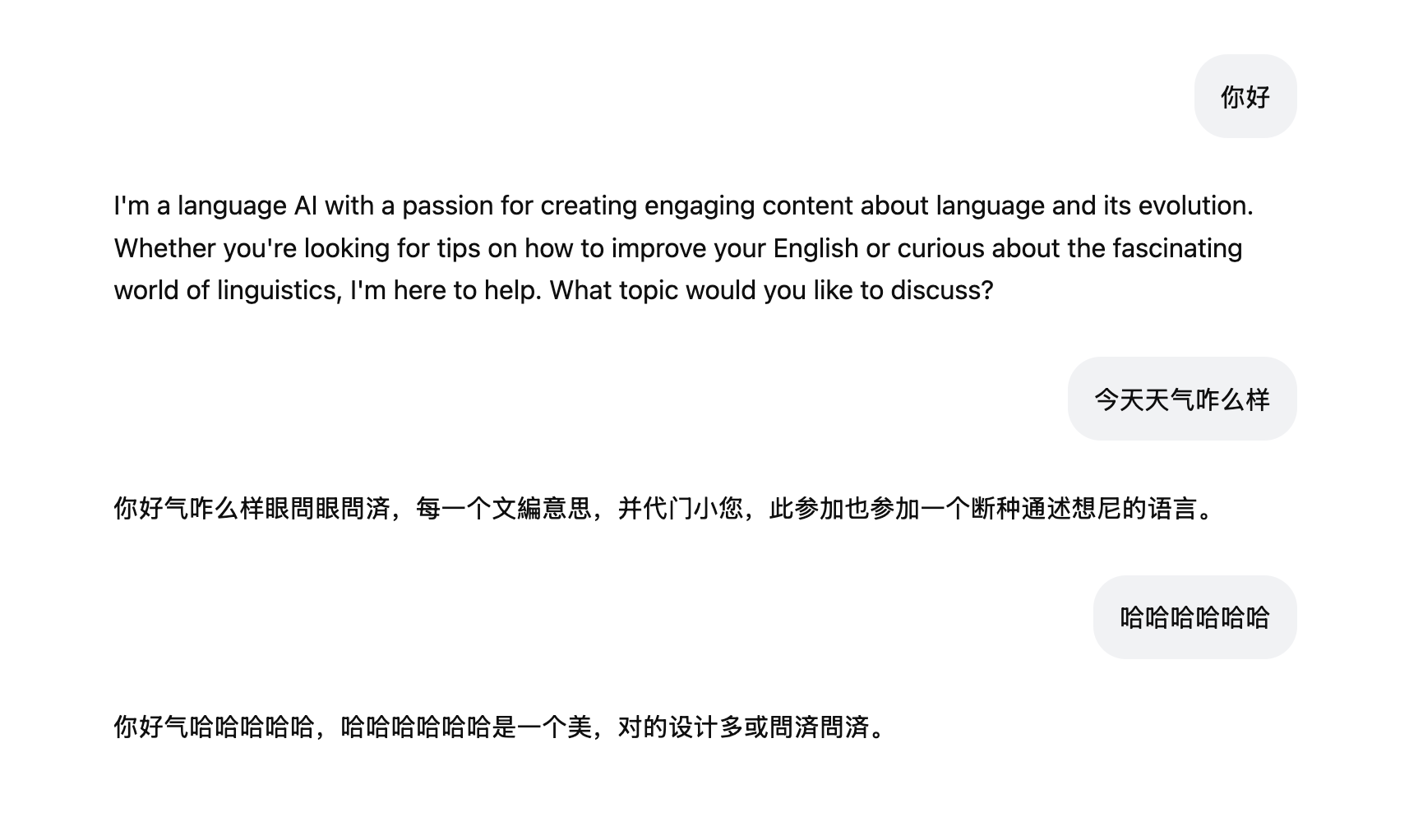 I totally don't know what it's talking about, but it's fun to see the performance.
I totally don't know what it's talking about, but it's fun to see the performance.
 Want to know the rest of the story? Try it out yourself!
Want to know the rest of the story? Try it out yourself!
Contact
Questions? Reach out via GitHub Issues or connect with me on LinkedIn.
Want to collaborate? I'm actively seeking opportunities in ML research/engineering, particularly at the intersection of deep learning and biology. Let's chat!